Na školeních často dostávám otázku, proč moje projekty nezačínají definicí CLAUDE.md. Primárně proto, že dlouhodobě mám zkušenost, že u postupně budovaného projektu není přínos tohoto souboru vygenerovaného automaticky z popisu projektu nijak zasadní. Teď to potvrzují i provedené studie. Pojďme se tedy podívat na příčiny i to, jak můžete své claude/agent soubory zlepšit.
Kontextové soubory jako CLAUDE.md nebo AGENTS.md jsou v roce 2026 de facto standard pro agentní vývoj. Anthropic, OpenAI, Cursor i další doporučují vytvářet kontextové soubory pro repozitáře, aby AI agenti lépe chápali kódovou základnu. Vývojáři s tím tráví čas, firmy to přidávají do onboardingových procesů. Ale funguje to?
Výzkumníci z ETH Zurich a LogicStar.ai (Maran, Schluntz, Tschannen & Vechev, únor 2026) provedli první kontrolovaný experiment. Výsledky jsou spíše rozpačité. Zjednodušeně řečeno: soubory pomáhají spíše málo.
Co testovali
Autoři vzali 4 kódovací agenty — Claude Code (Sonnet 4.5), Codex (GPT-5.2), Codex (GPT-5.1 Mini) a Qwen Code (Qwen3-30B) — a testovali je na dvou benchmarcích:
SWE-bench Lite — 300 úloh z 11 populárních Python repozitářů (Django, Flask, Scikit-learn, Sympy…). Standardní benchmark pro opravy bugů. Agenti tyto repozitáře s vysokou pravděpodobností viděli v trénovacích datech.
AGENTBENCH — nový benchmark, který autoři vytvořili pro tuto studii. 138 úloh z 12 méně známých Python repozitářů s lidsky napsanými kontextovými soubory. Repozitáře byly vybrány záměrně tak, aby je agenti pravděpodobně neznali z trénování.
Každý agent řešil úlohy ve třech režimech:
- Bez kontextového souboru (baseline)
- S LLM-generovaným kontextovým souborem — vygenerovaným z kódu repozitáře pomocí Claude Code a Codex
- S lidsky napsaným kontextovým souborem — ručně připraveným autory studie
To dává solidní srovnání: stejná úloha, stejný agent, jediný rozdíl je přítomnost a typ kontextového souboru.
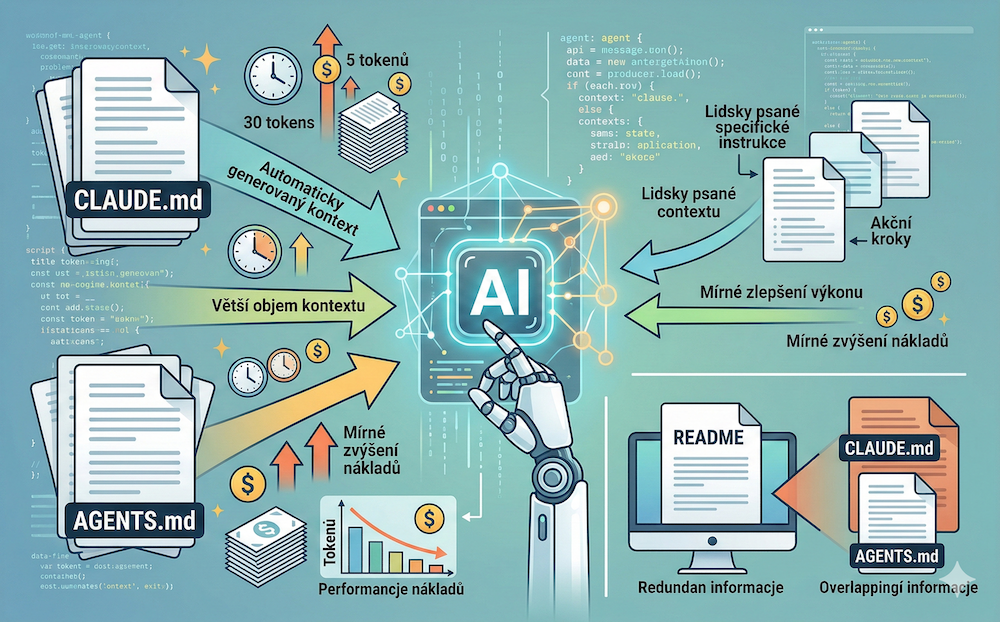
LLM-generované kontextové soubory výkon zhoršují
V 5 z 8 testovaných konfigurací (agent × benchmark) snížily LLM-generované soubory úspěšnost řešení. Průměrně o 0,5 % na SWE-bench Lite a o 2 % na AGENTBENCH. To není obrovský propad, ale rozhodně to není zlepšení.
Co je horší: náklady stoupají. Agenti s LLM-generovanými kontextovými soubory spotřebují o 20–23 % více kroků. A úměra je jasná. Více kroků = více tokenů = vyšší cena za každou vyřešenou úlohu. Platíte víc a dostáváte stejný nebo horší výsledek. Důvody jsou jednoduché - automaticky generované soubory nepřinášejí nic, co by agenti nezjistili jinak a naopak jsou dalším objemem do kontextu. Později se u toho na chvíli zastavíme.
Lidsky psané soubory pomáhají, ale mírně
Lidsky psané kontextové soubory přinášejí mírné zlepšení — v řádu jednotek procent, výraznější na AGENTBENCH (kde agenti repozitáře neznají) než na SWE-bench Lite. Není to dramatický skok. A i lidsky psané soubory zvyšují průměrný počet kroků (o 3,84 kroku na úlohu) a náklady (o 19 %). Platíte o pětinu víc za mírně lepší výsledek.
Agenti instrukce dodržují, ale nepomáhá jim to
Důležité zjištění: agenti kontextové soubory neignorují. Když soubor zmíní konkrétní nástroj (např. uv místo pip, nebo specifický test runner), agenti ho skutečně použijí — v průměru 1,6× za úlohu oproti 0,01× bez kontextového souboru. Problém není v tom, že by agenti kontext ignorovali. Problém je v tom, že ten kontext nepomáhá vyřešit úlohu.
Přehledy architektury jsou zbytečné
Téměř 100 % LLM-generovaných a 67 % lidsky psaných kontextových souborů obsahuje přehled struktury repozitáře — adresáře, moduly, jak spolu souvisí. Intuitivně to dává smysl: agent se rychleji zorientuje. Data to ale nepotvrzují. Počet kroků, než agent poprvé interaguje s relevantním souborem, se s kontextovými soubory prakticky nemění. Agenti se k cíli nedostanou rychleji. Místo toho tráví víc času čtením a procházením repozitáře — dělají víc průzkumu, ale ne efektivnějšího.
Klíčový experiment: co se stane bez dokumentace
Nejzajímavější nález přišel, když autoři z repozitářů odstranili veškerou existující dokumentaci — README, docs/, docstringy, komentáře. V tomto režimu:
- LLM-generované kontextové soubory náhle začaly pomáhat— průměrné zlepšení +2,7 %
- V některých případech dokonce překonaly lidsky psané soubory
Interpretace je jasná: LLM-generované kontextové soubory jsou z velké části redundantní s existující dokumentací v repozitáři. Agent se totéž dozví z README a zdrojového kódu. Kontextový soubor mu řekne to samé ještě jednou — a agent stráví čas jeho zpracováním, aniž by získal novou informaci.
Silnější model neznamená lepší kontextový soubor
Autoři testovali generování kontextových souborů pomocí různých modelů (GPT-5.2, GPT-5.1 Mini, Claude Sonnet). Výsledek: kvalita generujícího modelu nemá konzistentní vliv na užitečnost výsledného souboru. Investice do dražšího modelu pro generování kontextu se nevyplácí.
Co funguje a co ne: praktická doporučení
Na základě studie a jejích dat:
Nedělejte:
- Negenerujte
AGENTS.mdautomaticky pomocí LLM a nepředpokládejte, že to pomůže. Data ukazují, že u dobře zdokumentovaných repozitářů to výkon spíš zhorší a náklady zvýší. - Nepište obsáhlé přehledy architektury a adresářové struktury. Agenti tuto informaci získají z kódu samotného a váš přehled jim nepomůže se zorientovat rychleji.
- Neduplikujte informace z README nebo docs/. Pokud je něco v README, nemusí to být v
AGENTS.md.
Dělejte:
- Pokud kontextový soubor píšete, zaměřte se na specifické, akční instrukce: jaký balíčkovací systém použít (
uv, nepip), jaký test runner spustit, jaké repo-specifické CLI nástroje existují. Tyto instrukce agenti prokazatelně dodržují. - U repozitářů se slabou nebo chybějící dokumentací může kontextový soubor pomoct — právě protože vyplňuje informační mezeru, kterou jinak agent nemá jak překlenout.
- Udržujte kontextové soubory krátké a konkrétní. Každý řádek, který agent zpracuje, stojí tokeny a potenciálně odvádí pozornost od řešení úlohy.
Claude Code do nových verzí přidal funkci memory.md, která automaticky ukládá do markdown souborů popisy API a jiné důležité informace, které by musel Code opakovaně analyzovat a zjišťovat. Příště se u použití Memory zastavíme.
Limity studie
Studie má několik omezení, která je třeba mít na paměti:
Pouze Python. Všechny testované repozitáře jsou pythonové. Python je v trénovacích datech modelů masivně zastoupený, takže agenti ho zvládají i bez kontextu relativně dobře. U méně zastoupených jazyků (Rust, Elixir, Zig…) by kontextové soubory mohly mít větší přínos — ale to nevíme.
Pouze opravy bugů. SWE-bench i AGENTBENCH testují schopnost opravit existující bug. Neříkají nic o scénářích typu „implementuj nový feature od nuly” nebo „refaktoruj celý modul”, kde navigační kontext může hrát jinou roli.
Omezený rozsah. 138 instancí v AGENTBENCH a 300 v SWE-bench Lite je solidní, ale pro detekci malých efektů (řádově jednotky procent) není statistická síla obrovská.
Únor 2026. Agenti se rychle vyvíjejí. Výsledky platí pro testované verze Claude Code, Codex a Qwen Code. Budoucí agenti mohou kontext využívat efektivněji.
Závěr
Studie ukazuje, že moje puristické přesvědčení, že netřeba si do Claude Code přidávat hromadu přívěšků a doplnění, je v zásadě správné. Anthropic tento vývojářský nástroj rychle posouvá kupředu a veškerá zlepšení se snaží integrovat a vyhodnocovat jejich přínos. Takže pokud může přidat definiční sady ideálních postupů pro vývoj v nejrozšířenějších jazycích, udělal to - a asi to bude průběžně doplňovat. Příprava agentních souborů má smysl u legacy platforem, u specialitek. Současný hype kolem AGENTS.md a kontextových souborů není podložený daty. LLM-generované soubory v kontrolovaných testech výkon nezlepšují a zvyšují náklady. Lidsky psané soubory pomáhají mírně, ale jen pokud obsahují specifické, nezbytné instrukce — ne přehledy architektury.
Než strávíte odpoledne psaním dokonalého CLAUDE.md či AGENTS.md, zvažte, jestli váš čas nemá větší hodnotu jinde. A pokud ho přesto píšete, buďte struční a konkrétní. Rozhodně nemusíte zoufale vyhledávat ‘claude/agents.md’ soubory, které doporučují různé stránky, žádný smysl to nemá. Dříve možná přidávaly tyto soubory určitou vrstvu postupů, co dělat a jak postupovat, ale dnes už to daleko lépe vědí jednotliví vývojoví agenti sami o sobě a není třeba jim to explicitně vysvětlovat.
To mi připomíná, že jsem chtěl aktualizovat článek, jak vytvářet dobrý claude.md soubor pro Claude Code.