Sémantické vyhledávání patří mezi klíčové faktory ovlivňující kvalitu odpovědí AI asistentů při práci se zdrojovým kódem. Podle měření Cursoru zlepšuje přesnost odpovědí v průměru o 12,5 procent a zvyšuje pravděpodobnost, že navržené změny kódu zůstanou v projektu zachovány. Problémem je, že vytvoření prohledávatelného indexu pro rozsáhlé repozitáře může trvat hodiny, přičemž sémantické vyhledávání není dostupné, dokud není zpracováno alespoň 80 procent souborů. Cursor nyní představil nový přístup, který tento čas dramaticky zkracuje díky sdílení indexů mezi členy týmu.
Cursor: Merkle stromy a sdílené indexy
Základem řešení v Cursoru jsou Merkle stromy, datová struktura původně navržená pro efektivní ověřování integrity dat. Každý soubor v projektu dostane kryptografický hash a tyto hashe se hierarchicky kombinují do jediného kořenového hashe, který reprezentuje celý stav repozitáře. Když vývojář upraví soubor, změní se pouze hashe tohoto souboru a nadřazených adresářů až ke kořeni. Cursor porovná lokální a serverový Merkle strom a synchronizuje pouze větve, kde se hashe liší.
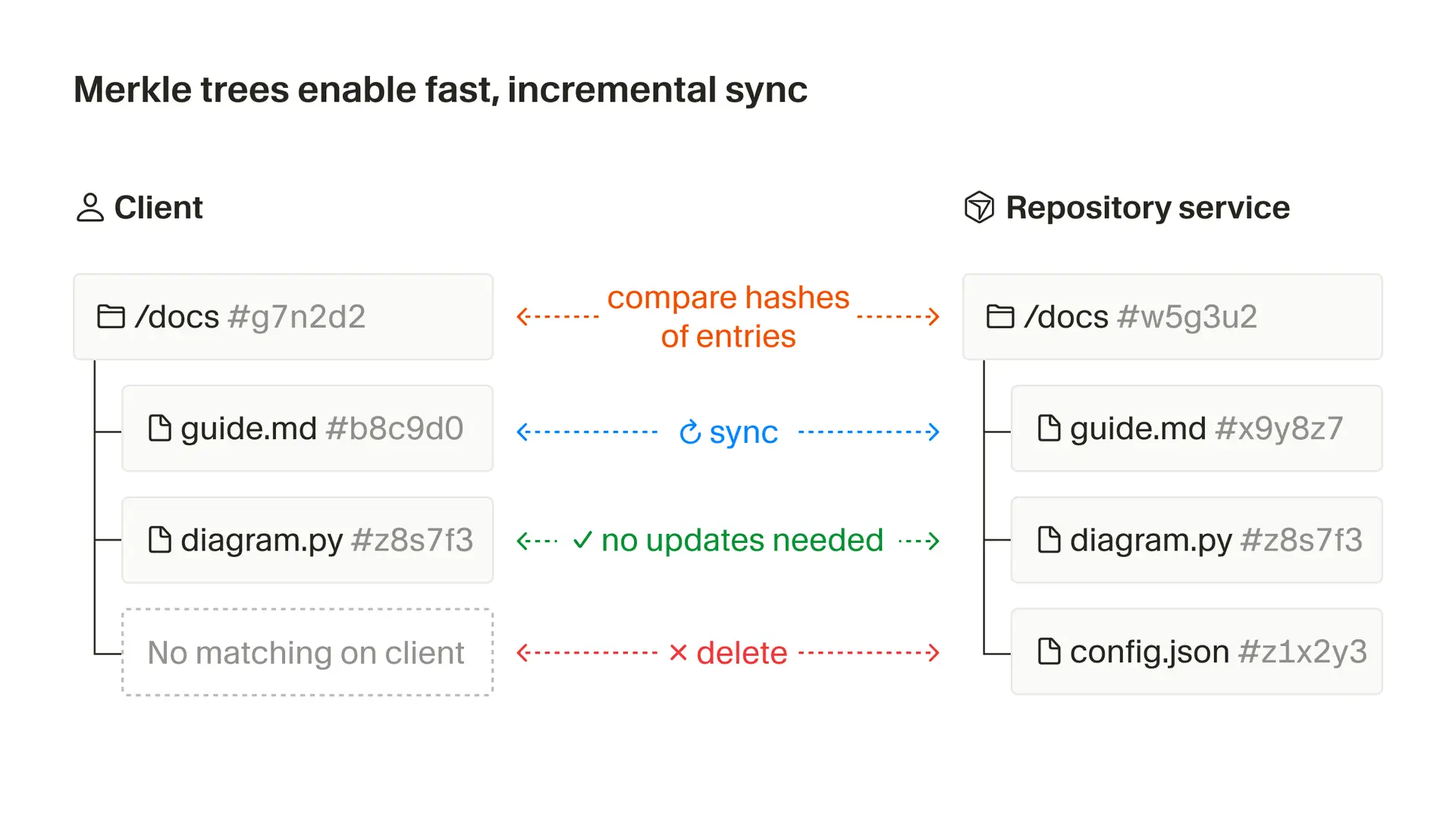
Pro projekt s padesáti tisíci soubory představují samotné názvy souborů a jejich SHA-256 hashe přibližně 3,2 MB dat. Bez stromové struktury by se toto množství přenášelo při každé aktualizaci. S Merkle stromem Cursor prochází pouze větve se změnami, což výrazně snižuje objem přenášených dat.
Po detekci změn Cursor rozdělí soubory na syntaktické fragmenty a vytvoří pro ně vektorové reprezentace (embeddingy). Tyto embeddingy ukládá do vektorové databáze Turbopuffer a kešuje je podle obsahu fragmentu. Nezměněné fragmenty využijí keš a nevyžadují opětovný výpočet.
Klíčovou inovací je znovupoužití indexů mezi členy týmu. Analýza ukázala, že klony stejného repozitáře mají v rámci organizace průměrně 92procentní podobnost. Když nový uživatel otevře projekt, klient vypočítá Merkle strom a z něj odvodí takzvaný similarity hash, který funguje jako souhrn obsahu souborů. Server tento hash použije k vyhledání podobného existujícího indexu ve vektorové databázi. Pokud najde shodu nad stanovenou hranici, použije tento index jako výchozí bod.
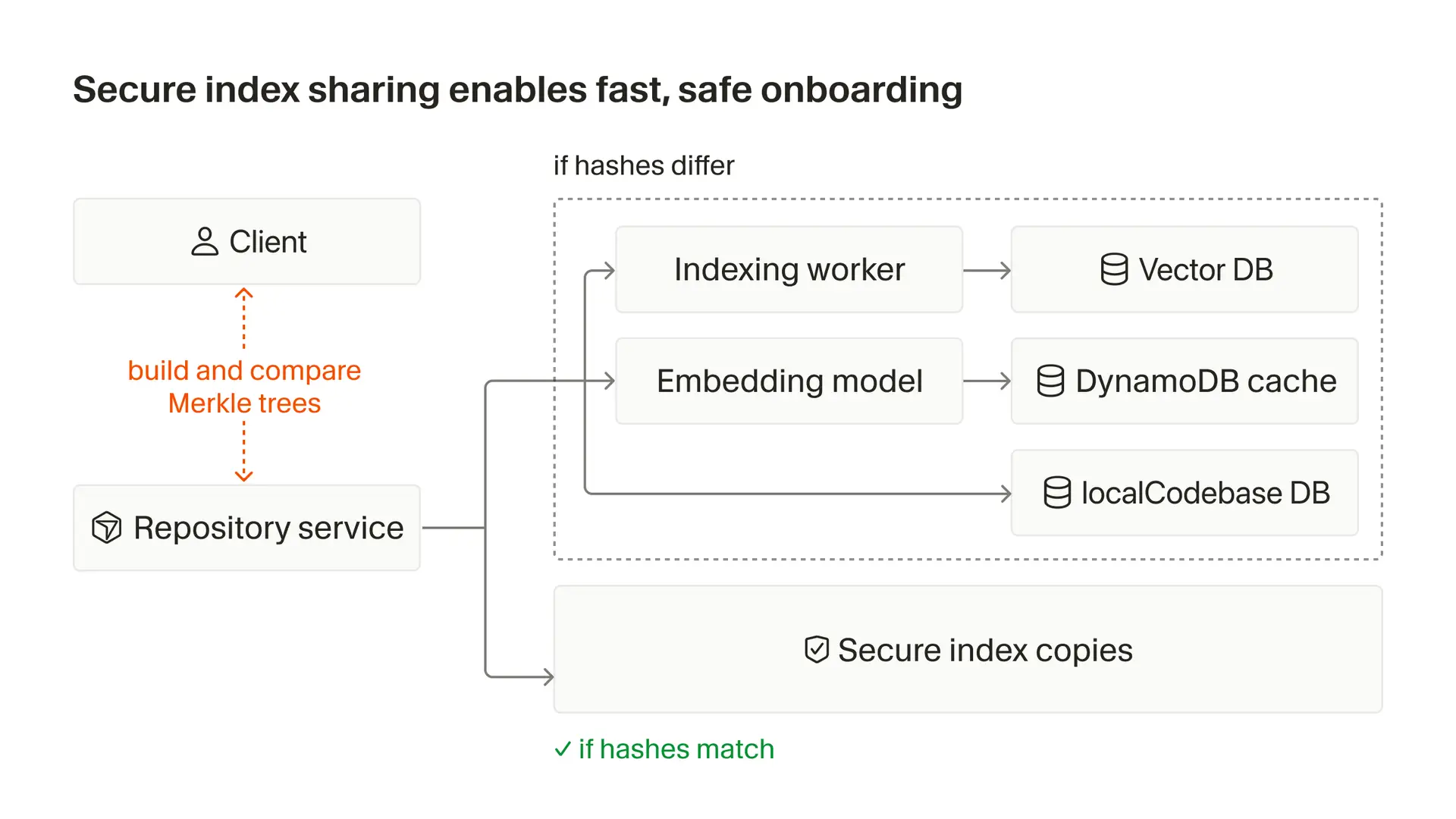
Kopírování indexu probíhá na pozadí a uživatel mezitím může provádět sémantické dotazy proti původnímu indexu. Pro zajištění bezpečnosti využívá Cursor kryptografické vlastnosti Merkle stromu. Klient nahraje svůj kompletní Merkle strom jako důkaz přístupu k souborům. Server při vyhledávání filtruje výsledky porovnáním hashů. Pokud klient nemůže prokázat, že soubor má, výsledek se mu nezobrazí.
Dopad na výkon je značný. Pro mediánový repozitář klesá čas prvního dotazu ze 7,87 sekundy na 525 milisekund. Na 90. percentilu z 2,82 minuty na 1,87 sekundy. Na 99. percentilu pak ze 4,03 hodiny na 21 sekund.
Claude Code: Agentní vyhledávání místo indexů
Anthropic u svého nástroje Claude Code zvolil fundamentálně odlišný přístup. Jak uvádí oficiální dokumentace, Claude Code nepoužívá předběžné indexování codebase vůbec. Místo toho má k dispozici sadu nástrojů pro navigaci v kódu na vyžádání. Když potřebuje něco o projektu zjistit, použije vyhledávací nástroj založený na grep a čte soubory podle potřeby.
Anthropic argumentuje, že tento přístup je flexibilnější a že Claude Code je dostatečně schopný prohledávat codebase a shromažďovat potřebný kontext za běhu. V praxi to ale znamená vyšší spotřebu tokenů, protože model musí při každém dotazu znovu procházet relevantní části kódu, přičemž relevanci udává to, zda najde očekávaná klíčová slova ve zdrojovém kódu.
Toto omezení vedlo komunitu k vytvoření rozšíření. Projekt Claude Context od společnosti Zilliz přidává sémantické vyhledávání pomocí protokolu MCP (Model Context Protocol). Řešení využívá vektorovou databázi Milvus a hybridní vyhledávání kombinující BM25 s hustými vektory. Podle vlastních měření dosahuje 40procentní úspory tokenů při srovnatelné kvalitě vyhledávání. Existuje i lokální varianta běžící zcela na uživatelově počítači s modelem EmbeddingGemma od Google, která nevyžaduje žádné API klíče ani cloudové služby. Objevují se i další nástroje, které se situaci snaží kreativně řešit, například GrepAI, ale pravda je, že Claude Code si s vyhledáním relevantního kusu kódu poradí dosti dobře, byť za cenu konzumace tokenů. Sám ovšem s těmito nástroji nemám aktivní zkušenost.
Na GitHubu Claude Code existuje otevřený požadavek na přidání indexování, který nasbíral značnou podporu komunity. Anthropic jej označil jako duplikát, což naznačuje, že se touto funkcionalitou interně zabývá.
GitHub Copilot: Okamžité vzdálené indexování
GitHub Copilot přešel v březnu 2025 na takzvané okamžité indexování. Dříve trvalo vytvoření sémantického indexu přibližně pět minut, nyní se většina repozitářů zpracuje během několika sekund, maximálně do 60 sekund.
Copilot používá hybridní strategii. Primárně se spoléhá na vzdálené indexy budované na infrastruktuře GitHubu z výchozí větve repozitáře. Tyto indexy jsou sdílené mezi všemi uživateli s přístupem k repozitáři. Pro lokální změny Copilot sleduje rozdíly oproti indexovanému commitu a kombinuje vzdálené vyhledávání s prohledáváním lokálně upravených souborů.
Pokud lokální diff přesáhne 2000 souborů nebo 70 procent workspace, Copilot přepne na jiné strategie. Pro menší projekty (do 750 souborů) VS Code automaticky buduje pokročilý lokální index. Pro projekty mezi 750 a 2500 soubory lze lokální index spustit ručně. Nad 2500 souborů bez vzdáleného indexu Copilot využívá základní index s jednoduššími algoritmy optimalizovanými pro lokální běh.
GitHub nespecifikuje, jaký embeddingový model používá. Jde o proprietární systém optimalizovaný pro zdrojový kód, koncepčně podobný modelům jako text-embedding-ada-002 od OpenAI, ale vyladěný pro práci s kódem.
Warp: Indexování metadat
Můj oblíbený terminálový nástroj Warp.dev nabízí indexování codebase jako součást svých AI agentů. Při otevření git repozitáře Warp automaticky začne indexovat zdrojový kód. Indexování však pracuje na rudimentálnější úrovni než konkurenční nástroje. Podle dostupných informací Warp indexuje pouze metadata jako názvy funkcí, což agentovi umožňuje mít přehled o codebase a detailněji prozkoumat soubory, jejichž funkce se zdají relevantní pro dokončení úkolu.
Počet indexovaných codebase a maximální počet souborů na codebase závisí na tarifu. Všechny tarify podporují indexování alespoň 5000 souborů na codebase. Pro velké codebase Warp podporuje ignore soubory (.warpindexingignore) umožňující kontrolu nad tím, co se indexuje. Kód indexovaný touto funkcí se podle dokumentace nikdy neukládá na serverech Warpu.
Pro codebase, které nelze indexovat, Warp agenti stále fungují pomocí grep, find a dalších terminálových příkazů pro získávání kontextu. Na GitHubu existuje požadavek na podporu vektorového indexování pro velké codebase.
Kilo Code a další nástroje
Rozšíření VS Code Kilo Code přidalo experimentální indexování codebase se sémantickým vyhledáváním ve verzi 4.32.0. Funkce automaticky indexuje projekt a umožňuje sémantické vyhledávání napříč celým projektem. Kilo Code kombinuje tuto funkcionalitu s takzvanou Memory Bank pro hybridní manuální a automatizovanou kontrolu informací o codebase.
Existuje také řada samostatných MCP serverů pro indexování, například Code-Index-MCP s podporou 48 programovacích jazyků a dotazy pod 100 milisekund. Tyto nástroje lze integrovat s libovolným AI asistentem podporujícím protokol MCP.
Pokud potřebujete pracovat s velmi rozsáhlými codebase, stojí ještě za úvahu Augment Code a jeho Context Engine.
Srovnání přístupů
| Nástroj | Typ indexování | Sdílení mezi uživateli | Lokální varianta | Embedding model |
|---|---|---|---|---|
| Cursor | Vektorové s Merkle stromy | Ano (v rámci týmu) | Ne | OpenAI/vlastní |
| Claude Code | Žádné (agentní grep) | Neaplikovatelné | Ano | Neaplikovatelné |
| GitHub Copilot | Vektorové vzdálené | Ano (celý repozitář) | Omezené (do 2500 souborů) | Proprietární |
| Warp | Metadata (názvy funkcí) | Ne | Ano | Nespecifikováno |
Přístupy se liší podle filozofie nástroje. Cursor a GitHub Copilot vsadily na předpočítané vektorové indexy pro rychlé sémantické vyhledávání. Claude Code preferuje flexibilitu agentního přístupu za cenu vyšší spotřeby tokenů. Warp jako terminálový nástroj nabízí základnější indexování zaměřené na metadata.
Pro týmy pracující s rozsáhlými codebase představuje Cursor způsob sdílení indexů pomocí Merkle stromů zajímavé řešení problému opakovaného indexování. Redukce času prvního dotazu z hodin na sekundy může výrazně zlepšit onboarding nových členů týmu nebo přechod mezi vývojovými stroji. Zároveň kryptografické ověřování přístupu zajišťuje, že uživatelé vidí pouze výsledky pro kód, který skutečně mají k dispozici.