Tento týden je na nové AI modely výživný. Google se přidal a vydal nové Gemini 3.1 Pro Preview, aniž by stihl vydat finální verzi 3 Pro. Máme i nezávislé výsledky testů, takže - jaké je nejnovější Gemini?
Články o ostatních představených modelech:
Co Gemini 3.1 Pro přináší
Gemini 3.1 Pro Preview je desetinkový upgrade modelu 3 Pro, takže od něj nečekejte zásadní novinky, kromě toho, že je lepší a silnější. Pokud jste chtěli něco nového, tak den před tím Google přidal do Gemini model Lyria pro generování hudby.
Co je na Gemini 3.1 hlavně zajímavé? Podle Intelligence Index Artificial Analysis vede o 4 body před Claude Opus 4.6. Jde o agregovaný ukazatel sestavený z deseti dílčích benchmarků – nikoli o jedno číslo vytržené z kontextu, ale o syntetický pohled na schopnosti modelu jako celku. Rozdíl čtyř procentních bodů je rozdíl měřitelný, nikoliv však dramaticky podstatný a je to spíše na hranici měřitelné nejistoty. Ale vezměmě si konkrétnější přirovnání: na benchmarku GDPval-AA, který je součástí indexu a měří reálné agentní úkoly, je rozdíl mezi Gemini 3.1 Pro Preview a Sonnet 4.6 přes 300 Elo bodů – to je rozdíl jako mezi průměrným šachistou a mistrem.
Oproti předchůdci Gemini 3 Pro Preview přináší tato verze výrazná zlepšení ve třech oblastech: vědecké uvažování a znalosti, kódování a – možná nejpodstatnější – dramatický pokles halucinací. Na testu AA-Omniscience, který měří tendenci modelu vymýšlet si fakta, které nezná, Gemini 3.1 Pro Preview zlepšil skóre oproti předchůdci o 38 procentních bodů. Takový skok není marginální vylepšení – je to kvalitativní změna chování modelu.
Kontextové okno zůstalo na 1 milionu tokenů, stejně jako cenotvorba: $2 za milion vstupních tokenů, $12 za milion výstupních tokenů. Nově model podporuje volání nástrojů, strukturované výstupy a JSON mode.
Co benchmarky skutečně říkají
Z benchmarků vidíme, že Gemini 3.1 Pro je nejsilnější v oblasti abstraktního a vědeckého uvažování, fyzikálních úloh na výzkumné úrovni a práce s nástroji v agentním prostředí.
Oproti tomu Claude Opus 4.6 je silnější v reálných agentních úkolech: na GDPval-AA, kde modely pracují autonomně s webovým prohlížečem a příkazovou řádkou na skutečných kancelářských úlohách, dosahuje Opus 4.6 skóre 1606 Elo, zatímco Gemini 3.1 Pro Preview jen 1316 – čtvrté místo za Sonnet 4.6 (1633), Opus 4.6 a GPT-5.2. GDPval-AA je přitom měřen nezávislou stranou, nikoli Googlem.
GPT-5.3-Codex – pozor, nejde o obecný model, ale o specializovaný kódovací agent vydaný OpenAI 5. února 2026 – je nejsilnější v terminálových a kódovacích úlohách vyžadujících autonomní práci v shellu. Na Terminal-Bench 2.0 dosahuje 77,3 %, na SWE-Bench Pro vede mezi srovnávanými modely. Je ale nutné zdůraznit: GPT-5.3-Codex je úzce profilovaný nástroj pro inženýrské workflow, nikoli všestranný frontierový model srovnatelný s Gemini 3.1 Pro nebo Opus 4.6.
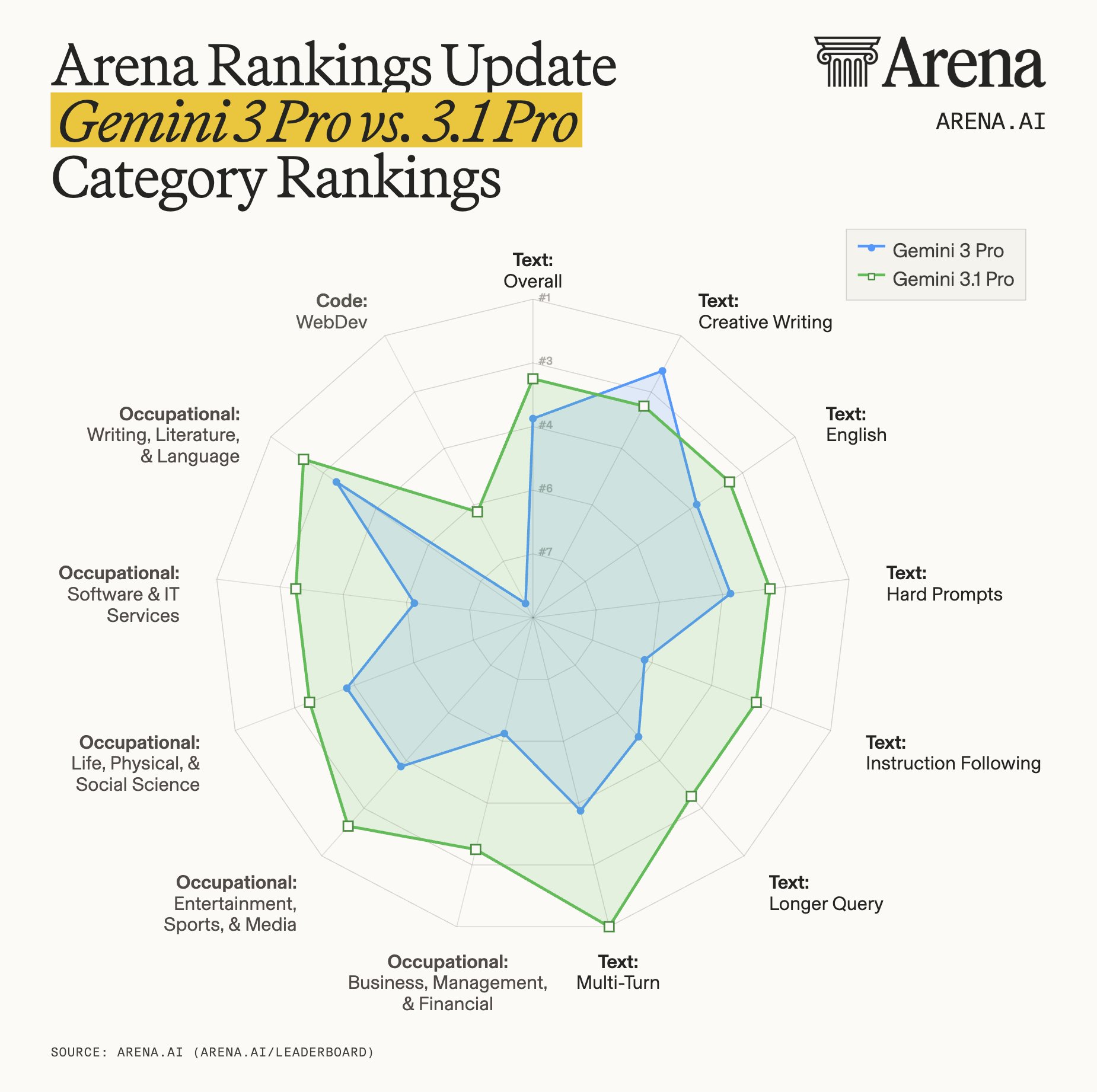
Arena leaderboard, kde modely hodnotí lidé v přímých soubojích, přináší konzistentní obraz: Gemini 3.1 Pro Preview vede mezi všemi testovanými modely v matematice, v obecném textu se drží těsně za dvojicí Opus 4.6 (rozdíl 5 Elo bodů, statisticky bezvýznamný), ale v kódování hodnoceném lidmi klesá na šesté místo za čtyři modely Anthropic a GPT-5.2-high. Dva nezávislé způsoby měření – automatizované benchmarky Artificial Analysis i hlasování uživatelů – ukazují shodně: Gemini 3.1 Pro Preview exceluje v uvažování a vědě, v reálném kódování a agentních úkolech za Claudy zaostává. O přechodu na Gemini CLI tedy není zatím nutné uvažovat.
Klíčová výhoda: cena a efektivita
To, co na čísla nečiní dostatečný dojem při prvním pohledu, vyjde najevo při pohledu na provozní náklady. Artificial Analysis provozuje celý Intelligence Index jako standardizovaný agentní benchmark – a zaznamenal, kolik tokenů každý model potřeboval. Gemini 3.1 Pro Preview spotřeboval přibližně 57 milionů tokenů, zatímco Claude Opus 4.6 (max) 160 milionů a GPT-5.2 (xhigh) ještě více. Celková cena benchmarku pro Gemini 3.1 Pro Preview: $892. Pro Opus 4.6: přes $2 000.
Gemini 3.1 Pro Preview tedy dosahuje vyššího skóre v celkovém Intelligence Index za méně než polovinu ceny. Pro provozně citlivé projekty – a to je v dnešní produkční AI realitě většina – jde o argument, který se nedá přejít.
Jak to zapadá do aktuálního srovnání
Únor 2026 je zvláštním momentem pro AI průmysl. Během dvou týdnů přišly Anthropic (Sonnet 4.6, Opus 4.6), OpenAI (GPT-5.3-Codex) a nyní Google (Gemini 3.1 Pro Preview) každý s modelem, který v něčem vede benchmarkové tabulky. Žádný z nich nevede ve všem.
Gemini 3.1 Pro Preview vedoucí celkový Intelligence Index o 4 body před Opus 4.6 při ceně nižší než polovina není nepodstatný výsledek. Zároveň je fér říct, že 4 body na agregovaném indexu jsou statisticky blízko a na reálných agentních úkolech (GDPval-AA) Gemini 3.1 Pro Preview za Claudy stále zaostává.
Nejlepší model záleží na tom, co měříte. Pro vědecké uvažování a znalostní benchmarky: Gemini 3.1 Pro Preview. Pro autonomní agentní práci s nástroji v produkci: Sonnet 4.6 nebo Opus 4.6. Pro terminálové kódovací workflow: GPT-5.3-Codex. Pro nákladově citlivé projekty s přijatelnými kompromisy ve výkonu nebo potřebu suverenity nad daty: GLM-5.
Co je nepochybné: Google se vrátil do čela “SOTA” modelů (State Of The Art) – poprvé od doby, kdy Anthropic a OpenAI v průběhu roku 2025 vedení přebraly. A vrátil se způsobem, který si nezakoupil jen přidáváním tokenů. Blahopřeji!
Zdroje dat a testů: Artificial Analysis Intelligence Index (nezávislé měření, pre-release přístup poskytnutý Googlem), Google DeepMind oznámení Gemini 3.1 Pro Preview, OpenAI system card GPT-5.3-Codex (5. 2. 2026), Zhipu AI GLM-5 (11. 2. 2026), Medium/Maxime Labonne – GLM-5 analýza.